【Python】从迭代器到生成器:小内存也能处理大数据
Hey guys,今天我想要分享的主题是,迭代器和生成器。
它们在处理大量数据时非常有用,可以帮助我们节省内存资源。
让我们开始吧。
为什么有的对象可以使用 for 循环迭代,有的不可以?
我们知道,有的对象可以用 for 循环,比如字符串或者列表,有的对象不可以,比如整数。
我在这里定义了字符串,列表和整数,分别对它们使用 for 循环,就可以看到字符串和列表能够正常工作,而整数报错。
在这里要引入一个概念,Python 中,能够使用 for 循环迭代的对象叫可迭代对象,也叫 Iterable。Iterable 会包含 __iter__ 方法。
我们可以通过 hasattr 函数查看一个对象是否有某个属性或者方法,如果你对字符串、列表、整数分别使用这个方法,就会看到字符串和列表都有这个方法,整数没有。
像 __iter__ 这样前后有两个下划线的方法,叫特殊方法,也叫魔法方法。一般用来控制对象要怎么回应 Python 的内置行为。如果你不太熟悉特殊方法,可以查看我之前介绍特殊方法的文章。
那么,__iter__ 这个方法可以做什么呢,为什么有了它就可以在for循环中进行迭代?
for 循环的原理
这和 for 循环的原理有关,这是 for 循环的原理流程图。
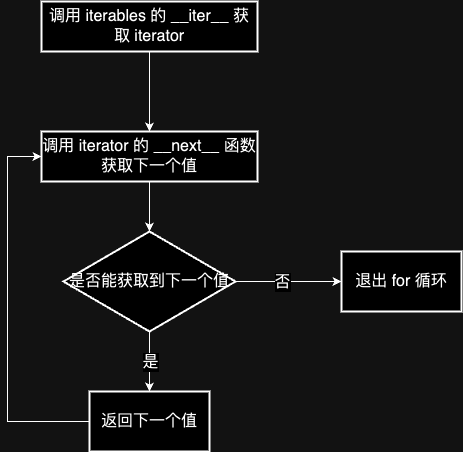
for 循环时,Python 会先使用 iter() 从这个可迭代对象中获取迭代器。然后再调用这个迭代器的 next 方法获取下一个元素。没有下一个元素时,就跳出循环。
这里也许你会有疑惑,因为还没有解释什么是迭代器,但至少现在我们会明白两点:
- 我们会从可迭代对象中获取迭代器;
- for 循环中获取下一个值是通过迭代器的 next 方法。
为了让我们更好地理解 for 循环的原理,我们来使用 while 循环完成这个流程
1
2
3
4
5
6
7
8
9
l = [1,2,3]
it = iter(l) # 先从可迭代对象中获取迭代器
while True: # 然后使用一个循环
try:
print(next(it)) # 对迭代器一直调用 next
except StopIteration: # 直到捕获到 stopiteration
break # 跳出循环
你也许会有疑问,为什么上面是有下划线的 iter 和 next,而这段代码中没有。是因为它们是等价的。我使用 iter(my_str) 就等价于调用 my_str.__iter__ 。
这里的 StopIteration 相当于流程中的否,当迭代器没有下一个值时,就会 raise StopIteration 的异常。
运行一下你会看到,和我们以往使用 for 的结果一样。现在你应该能够理解 for 循环的原理了。
现在让我们进入今天的主题,迭代器。
迭代器是什么?
什么是迭代器?我想先给出迭代器的定义,迭代器需要包含两个魔法方法 __iter__ 和 __next__。可以说,只要包含了这两个方法的对象,就是迭代器。
那么这两个方法用来做什么?
- 对于 iter。刚刚说过,可迭代对象的
__iter__会返回一个迭代器,而迭代器的__iter__会返回迭代器本身。 - 对于next。每次调用都可以得到下一个要迭代的值。特点是会一直往下走,不会回头,直到没有下一个值时,raise 一个 StopIteration。此时,这个迭代器就用完了,我们再也不能从这个迭代器里面获取值。如果想再次迭代,就需要对可迭代对象调用 iter(),重新创建迭代器。
迭代器的实际应用
接下来我们需要知道什么时候使用迭代器,以及迭代器的内部构造,我想尝试在一个实际例子中使用迭代器。
这里有一个我刚刚伪造的十万行的日志文件。其中包含一些信息。操作时间,操作人员,以及操作类型。我这个例子非常简单,在实际应用中,要处理的文件会大得多,单个文件几G也是常有的事。
现在我想要对文件中的每一行进行处理,执行一个名为 process_line 的函数。
1
2
def process_line(line):
pass
具体的处理过程我使用 pass 表示,因为这不是本次的重点,我不希望焦点分散。
一个常见的处理方式是,将文件全部载入,再一行行处理。
1
2
3
4
5
6
7
filepath = './logfile.log'
with open(filepath, 'r') as file:
lines = file.readlines()
for line in lines:
process_line(line)
使用变量 lines 将文件内容以列表的形式存在内存中,然后一行行进行处理。毫无疑问这个内存占用会相当大。
我想引入一个模块 tracemalloc 来帮助我确认程序的内存使用情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import tracemalloc
tracemalloc.start() # tracemalloc.start() 表示开始跟踪内存分配
filepath = './logfile.log'
with open(filepath, 'r') as file:
lines = file.readlines()
for line in lines:
process_line(line)
current, peak = tracemalloc.get_traced_memory() # 获取当前的内存使用量,以及start到现在的内存使用峰值
print(f"Current memory usage: {current / 1024**2} MB")
print(f"Peak memory usage: {peak / 1024**2} MB")
tracemalloc.stop() # 停止跟踪内存分配
让我们运行看看这个程序会占用多大内存。
答案是 10 MB,听起来不算大,但别忘了,这个程序还什么处理都没做呢,10 MB 对于一个还没有做什么实质性工作的程序来说,已经是一个很大的值了。而这还建立在我这个文件比较小的前提上。
那有什么更好的办法呢,既然我们是一行行进行处理,那我们就一行行取出。
我这里定义了一个迭代器,来一行行取出。尽管这个例子有更简单的写法来使用迭代器,但我想用一个完整的迭代器类,来更好地展示迭代器的内部构造。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class LineIterator:
def __init__(self, filepath):
self.file = open(filepath, 'r')
def __iter__(self):
return self
def __next__(self):
line = self.file.readline()
if line:
return line
else:
self.file.close()
raise StopIteration
line_iter = LineIterator(filepath)
for line in line_iter:
process_line(line)
新建一个类,需要三个方法。用来构造实例的__init__,以及迭代器必须包含的 __iter__ 和__next__。
- 通过路径进行实例化,同时在构造时打开文件。这里的 open 和上面例子的 with open 不同是因为第一个例子用到了上下文管理器 context manager,可以自动打开和关闭文件。这也是 Python 一个很好用的特性,我会在之后的文章中做分享。
- 可迭代对象的
__iter__需要返回迭代器,所以迭代器的__iter__返回的是迭代器自己。 - 现在来到了重点,
__next__。它用于返回下一个元素,在这个例子中,我希望返回的下一个元素是下一行。所以我使用 readline 读取文件的一行。如果读取得到,就返回这行,如果读取不到了,就关闭文件,并 raise StopIteration。
这样我们就定义好了一个包含 __iter__ 和 __next__ 的迭代器。我们先使用路径将这个迭代器实例化,然后用 for 循环这个迭代器,就像我们刚刚对列表做的一样。for 会先从这个迭代器的 iter 方法中获取迭代器自己,然后再从 next 方法中不断获取下一个值。
再让我们看看这个过程会占多少内存,答案是不到 0.1 M。远小于我们使用列表。这完全可以理解,因为我们并没有把文件内容加载到内存中。
定制 __next__
理解了迭代器的基本构造后,我想稍微加一点点难度,让我们明白如何灵活使用迭代器。
我不想处理所有的行,我只想处理操作类型是 create 的行。也就是说,我希望这个 LineIterator 只会返回操作类型是 create 的行。
从文件中看到,要找到操作类型是 create 的行,可以将行使用 split 进行分割,分割为三个元素,然后看索引为 2 的元素是否是 Create。
我们来稍微修改 next 来筛选这些行。
1
2
3
4
5
6
7
8
def __next__(self):
line = self.file.readline() # 先读取一行
while line: ## 将这一段进行循环
if line.split('|')[2].strip() == 'create': # 通过split取到操作类型,判断是否是我要的create行
return line # 如果是的话就返回这行
line = self.file.readline() # 不是的话就继续往后取
self.file.close() # 如果已经取到了空行,就关闭文件,并 raise stopiteration
raise StopIteration
从迭代器到生成器
通过刚刚的例子,不知道你有没有一个感受:迭代器最重要的部分是 __next__ 方法,构造函数和 __iter__ 对于定义一个迭代器类来说有点累赘。
如果你有这个感受,那么有一个好消息。Python 有一个东西叫生成器,你可以理解为迭代器的简单实现。
这是一个简单的生成器函数,这个函数在调用时,不会返回具体的值,而是返回一个生成器。
1
2
3
4
5
6
7
def generator(n):
for i in range(n):
print('before yield')
yield i
print('after yield')
gen = generator(3)
这里的关键是,生成器函数会包含 yield 关键字。通过这个关键字,生成器会自动产生 __iter__ 和 __next__ 方法。
它的运行规则是在 yield 这行生成一个值,然后退出函数,下次进来时又从 yield 处继续。我在这里加两行打印语句,以便我们观察。
与迭代器相同,我们可以通过 next 看到生成器里面的值。
我们来试试看。
1
2
3
4
print(next(gen)) # 先打印一个 next 产生的值
print('---') # 再打印一个分割线
for i in gen: # 再打印 for 循环
print(i)
看看这个运行结果吧。
1
2
3
4
5
6
7
8
9
10
before yield 执行第一个next函数时,进入生成器函数
0 # yield 0,然后退出生成器函数
=== # 退出函数,打印分隔符
after yield # 再次进入生成器函数,从 yield 处继续
before yield # 进入一个生成器函数中新的循环
1 # yield 1 退出生成器函数,后面以此类推
after yield
before yield
2
after yield
现在你应该能够理解刚刚说的,从 yield 处退出,再从 yield 处继续了吧。
如果要在刚刚读取文件的例子使用生成器的话,可以这样写。
1
2
3
4
5
6
7
8
9
10
11
def line_generator(filepath): # 定义一个 line generator,filepath 作为传入的参数
with open(filepath, 'r') as file: # 打开文件
for line in file:
if line.split('|')[2].strip() == 'create':
yield line
else:
continue
line_gen = line_generator(filepath)
for line in line_gen:
process_line(line)
可想而知这个程序占用的内存也很小。
在实际应用中,比起自己定义迭代器,我们更多会使用生成器。
使用迭代器,或者说生成器的好处
现在我们来谈谈使用迭代器,或者说生成器的好处。
一是惰性计算,我们只有在处理这个元素的时候,才迭代到它或者生成它。这样可以很好地节省资源。
另一个原因是,生成器可以没有终点。以斐波那契数列举例,每一个值都是前两个值的和,我们可以定义一个生成器实现每次返回下一个数。
1
2
3
4
5
6
7
def fib_generator():
cur, nxt = 0, 1 # 先定义好数列的前两个数
while True:
yield cur # 返回一个数字,然后退出生成器函数
cur, nxt = nxt, cur+nxt # 再次进入生成器函数,更新两个数
fib_gen = fib_generator()
只要我们愿意,这个生成器可以一直生成下一个值,没有尽头。
但最好,我们还是设定一个执行的次数。
1
2
for _ in range(10):
print(next(fib_gen))
最后是一道题
最后,我准备了一道简单的题目,你可以尝试用它来验证你对迭代器生成器的了解。
定义一个生成器 multiplcation_generator 用来生成关于某个数字的乘法表。
比如使用 2 进行初始化,第一次产生的值是一个字符串,第二次依然是产生关于 2 的乘法一个字符串,只是从 1 变成了 2。以此类推 3 4 5。
1
2
3
4
5
6
7
8
def multiplcation_generator(x):
pass
multi_gen = multiplcation_generator(2)
next(gen) # '1 x 2 = 2'
next(gen) # '2 x 2 = 4'
next(gen) # '3 x 2 = 6'
next(gen) # '4 x 2 = 8'
最后
我希望通过这篇文章,能够帮助你了解如何使用迭代器和生成器,以便你在处理大型文件或者数据库之类的场景通过它们节约资源。
如果你有任何问题可以在下方的评论区留言,感谢你的阅读。